

How to Read Parquet Files in Python using Pandas, FastParquet, PyArrow or PySpark
Parquet is a columnar storage format for large datasets that is optimized for efficient compression and faster query performance. It is a popular choice for storing data in big data processing systems such as Hadoop and Apache Spark. You can save 70% of storage space if keep the file in Parquet than CSV file. But we can’t read a parquet file normally. We need to know how to read parquet file in Python effeciently. In this article you will understand how to open and read a parquet file in Python.To know more about parquet file format you can review my earlier article.
Table of Content
How to Read Parquet Files in Python
Key Concepts of Parquet File Format
How to Read Parquet File in Python with Pandas
How to Read Parquet File with PyArrow
Open Parquet File with Fastparquet
Key Concepts of Parquet File Format
Parquet Format: Parquet format is an efficient columnar storage method specifically designed to streamline the handling of extensive datasets in distributed processing setups.
Partitioning: The technique of segmenting a dataset into smaller sections determined by the values within one or multiple columns.
Pandas DataFrame: A structured data frame in Python consisting of labeled rows and columns, capable of accommodating various data types within its columns.
PyArrow: A Python open source software package that interfaces with the Apache Arrow C++ library, facilitating the manipulation and management of columnar data in a Python environment.
For Reading Parquet files in Python, you can use the following libraries:
How to Access Parquet files in Python with Pandas
Pandas is a popular Python library for data analysis and manipulation. It provides a convenient read_parquet() function that can be used to load parquet format files into pandas dataframes. To read parquet files using Pandas, simply pass the file path of the parquet file to the pd read parquet file function. For example, the following code reads the parquet file employees.parquet and loads parquet data into a Pandas DataFrame called df. This is how to read parquet file in Python Pandas. You must be interested to review pd read parquet in my another article.
#Install the Pandas Python Library
pip install pandas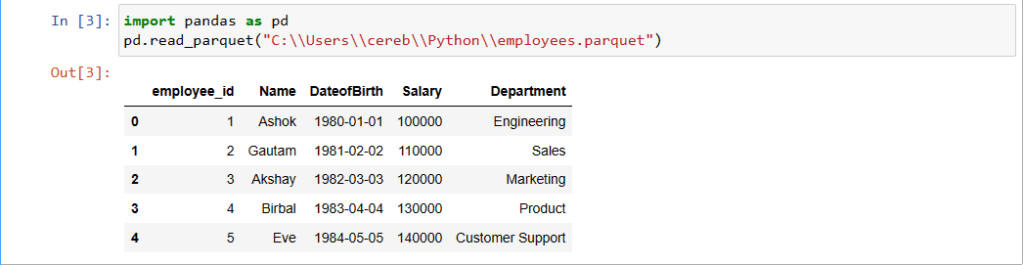
#import the pandas
import pandas as pd
# Read the file
df = pd.read_parquet('employees.parquet')
# Print the first few rows of the DataFrame
print(df.head())employee_name city date_of_birth
0 Vihaan Reddy Hyderabad 1995-07-19
Accessing Parquet File with PyArrow
PyArrow is a Python library with the Apache Arrow for working with columnar data. It provides a more efficient way to access the Parquet file than Pandas. This is how you can read parquet file python without pandas. You need to open parquet file python and read the parquet file using PyArrow.
To read a Python parquet file with PyArrow, you can use the read_table function to open parquet file in Python. For example, the following code reads the Parquet file employees.parquet and loads it into a PyArrow Table object called table:
#Install the PyArrow Python Library
pip install pyarrow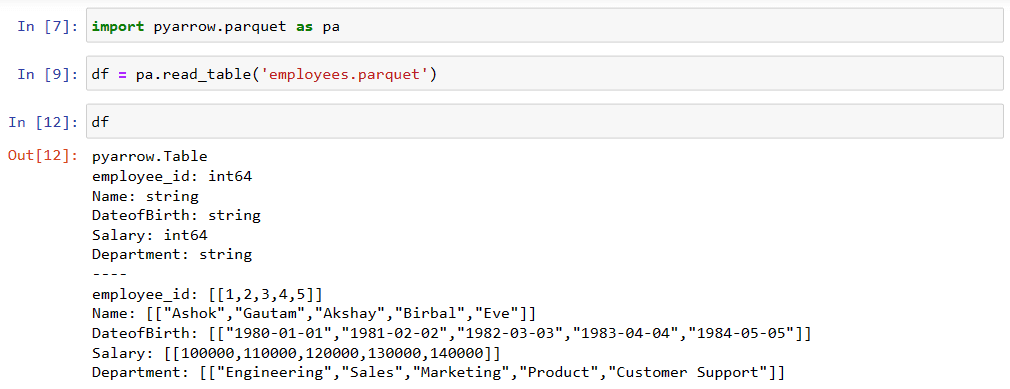
import pyarrow as pa
# parquet file pq.parquetfile
table = pa.read_table('employees.parquet')
# Print the first few rows of the Table
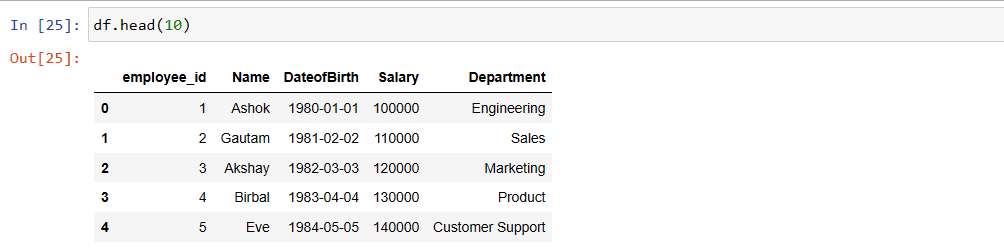
print(table.head())Convert the PyArrow Table object to a Pandas DataFrame
df = table.to_pandas()
# Print the first few rows of the DataFrame
print(df.head())Parquet Files with Fastparquet
Fastparquet is a Python library that is specifically designed for reading and writing Parquet files. It is faster than Pandas and PyArrow for reading Parquet files. In below section you will see how to open parquet file Python using FastParquet.
#Install the fastparquet Python Library
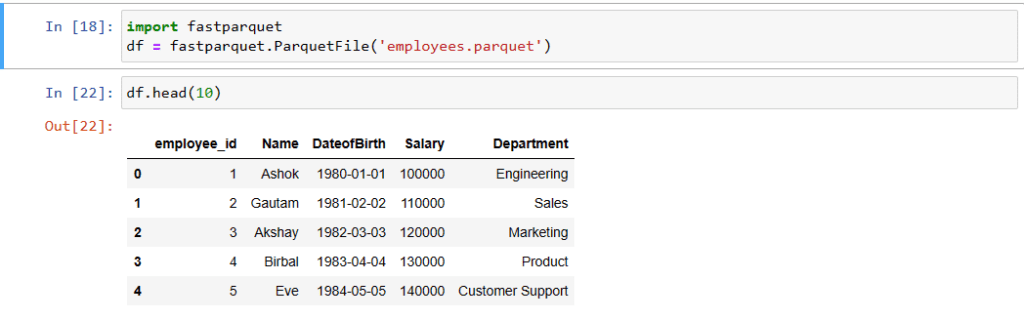
pip install fastparquetYou can access a Parquet file format with Fastparquet, you can use the ParquetFile() function. For example, the following code reads the Parquet file employees.parquet and loads it into a Pandas DataFrame called df:
import fastparquet
# Read the file with read parquet function
df = fastparquet.read('employees.parquet')
# Print the first few rows of the DataFrame
print(df.head(10))Parquet Files using PySpark
How to Open Parquet File using PySpark? PySpark is a great option to read large datasets including parquet files, you can use the read parquet function. This function takes the file path of the Parquet file as the argument and returns a Spark DataFrame. This way also you can read parquet file in python without Pandas library. Read my article about PySpark to know more about the functionality of pyspark.
For example, the following code reads the Parquet file employees.parquet and loads it into a Spark DataFrame called df to open parquet file python:
from pyspark.sql import SparkSession
# Create a SparkSession object
spark = SparkSession.builder.getOrCreate()
# Read the file using read parquet function
df = spark.read.parquet('employees.parquet')
# Print the first few rows of the DataFrame
df.show()If you install PySpark on Windows correctly and followed the steps as mentioned in the article you can read parquet files(read parquet) in PySpark
Conclusion
There are different ways to read Parquet files in Python. The best way to read the Parquet file depends on your specific needs. When you need a convenient and easy-to-use ways, then Pandas is a good option. If you need a more efficient way to read Parquet files, then PyArrow or Fastparquet are good options. But if you want to read a large parquet file (5 to 10 GB) PySpark is the most convinient and efficient way to open/read parquet files.
Using Parquet Files has several advantages. As Parquet file takes less space and effeciently stores data in file system as well as in cloud. You need to know how to store/import parquet file from Amazon S3. Also how to use this in Postgres using Foreign Data Wrapper.
I hope this this article was helpful. Please let me know in case of any questions, suggestion or feedback on this.



Pingback: pd.read_parquet: Efficiently Reading Parquet Files with Pandas
Pingback: How to Import Data from S3 (into PostgreSql) – Enodeas
Pingback: Postgres Parquet FDW: Foreign Data Wrappers in 10 Minutes
Pingback: What is Parquet File Format – Enodeas