

What is Apache Spark in Python?
In today’s world, data is generated at very rapid rate, making efficient data processing essential. Apache Spark and its Python API, PySpark, offer powerful solutions for handling big data. What is PySpark? PySpark allows parallel processing across distributed systems, making it incredibly fast and scalable. Whether you are a data scientist, engineer, or analyst, PySpark provides the tools to process large datasets efficiently. This guide will take you from the basics to advanced PySpark functionalities with clear explanations and real-world examples.
By the end of this guide, you will understand how to set up PySpark, manipulate large datasets, optimize performance, and build machine learning models.
What You Will Learn
- Understanding Big Data and Spark’s Role
- Setting Up PySpark
- RDDs (Resilient Distributed Datasets)
- Spark Architecture
- DataFrames and SQL
- Data Processing Fundamentals
- Handling Various Data Formats
- Advanced Data Operations
- Machine Learning with MLlib
- Spark Streaming
- Spark SQL and Hive Integration
- Performance Optimization
- Debugging and Troubleshooting
- Deployment and Cluster Management
- Best Practices and Advanced Features
What is Big Data?
Big data refers to large and complex datasets that are difficult to process using traditional data processing applications. It encompasses massive volumes of data generated at high velocity and varying in variety. Understanding big data is crucial in today’s digital age for extracting valuable insights and driving informed decision-making.
If your data exceeds the capacity of a local computer, which typically ranges from 0 to 32 gigabytes based on available RAM, consider these options:
- Utilize a RDMS system like Oracle, postgres, mySQL to store data on the hard drive rather than in RAM.
- Employ a distributed system, which disperses data across multiple machines or computers.
- Local processes leverage the computing resources of a single machine.
- Distributed processes tap into computational resources across multiple network-connected machines.
- Beyond a certain threshold, scaling out to numerous lower CPU machines becomes more feasible than scaling up to a single high-CPU machine.
- Distributed machines offer easy scalability; simply add more machines as needed.
- They also provide fault tolerance; if one machine fails, the network can continue operating.
- Now, let’s delve into the typical structure of a distributed architecture using Hadoop.
What is Spark (PySpark)?
Spark, an open-source project under the Apache Software Foundation, is a cutting-edge technology designed to efficiently process and manage big data. Developed at the AMPLab at UC Berkeley, Spark debuted in February 2013 and has rapidly gained traction due to its user-friendly interface and impressive speed. Spark serves as a flexible alternative to traditional MapReduce frameworks, offering enhanced performance and ease of use. It supports various data storage systems like Cassandra, AWS S3, and HDFS, making it versatile for diverse big data applications.
Spark’s core strength lies in its ability to handle complex data processing tasks with agility, leveraging in-memory computation for rapid data analysis and iterative algorithms. With its growing ecosystem and extensive libraries, Spark continues to revolutionize the big data landscape, empowering organizations to extract valuable insights from large datasets efficiently.
Here’s why it stands out:
- In-memory computing: Spark stores data in RAM, significantly speeding up processing.
- Distributed architecture: It processes data across multiple nodes in a cluster.
- Flexibility: Supports various programming languages including Python, Scala, and Java.
- Rich ecosystem: Includes libraries like MLlib (for machine learning), Spark SQL, and Spark Streaming.
- Better than Hadoop: Unlike Hadoop’s MapReduce, Spark processes data much faster due to in-memory computing.
PySpark Installation: Setting the Stage
Starting with PySpark? Make sure your setup is smooth. Here’s how to install PySpark and get started without hassle.
Before using PySpark, you need to set up your environment properly.
Prerequisites of PySpark
- Install Python (recommended version 3.8+)
- Install Java (JDK 8 or later)
- Install Apache Spark
Installation of PySpark
To install PySpark, use below pip command:
pip install pyspark
pip install findsparkFindspark helps PySpark locate its installation directory.
Setting Up Virtual Environment for PySpark
It’s recommended to use a virtual environment to manage dependencies:
python -m venv pyspark_env
source pyspark_env/bin/activate (Linux/macOS)
pyspark_env\Scripts\activate (Windows)Starting PySpark
pysparkThis launches the interactive PySpark shell.
Run PySpark in Jupyter Notebook
To run PySpark in Jupyter Notebook:
import findspark
findspark.init()
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("PySparkTutorial").getOrCreate()PySpark and IDE: A Symphony of Tools
To compose PySpark symphonies, equip yourself with the right tools. Spyder IDE and Jupyter Notebook stand as maestros in your PySpark orchestra. Ensure they are harmoniously installed and ready for your creative expressions.
Features and Advantages of PySpark (Python Spark Tutorial)
Let’s explore why Spark in Python stands out. Its features include in-memory computation, distributed processing, fault tolerance, lazy evaluation, and support for various cluster managers. This translates to applications running 100 times faster than traditional systems.
Advantages? PySpark is your go-to for processing data from various sources like Hadoop HDFS and AWS S3. It’s not just fast; it’s a game-changer for real-time data processing, thanks to its streaming capabilities.
PySpark vs. Traditional Systems
Time to bid farewell to the limitations of traditional systems. PySpark, with its in-memory processing and distributed nature, outshines traditional systems like MapReduce. It’s multi-language, supporting Java, Scala, Python, and R, providing flexibility for developers.
The PySpark community is vast, with giants like Walmart and Trivago utilizing its efficiency. If you’re into data science and machine learning, PySpark’s compatibility with Python libraries like NumPy and TensorFlow makes it a top choice.
Unveiling PySpark Architecture
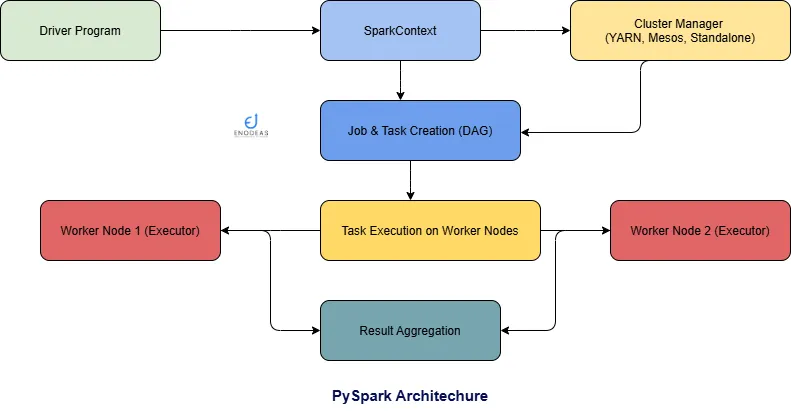
Dive into the architecture of PySpark, where the magic happens in a master-slave dance. Let’s demystify this structure in a way that’s crystal clear.
Master-Slave Architecture
PySpark operates on a master-slave architecture, where the master is aptly named the “Driver” and the minions are the “Workers.” Picture this: when you run a Spark application, the Driver creates a context as an entry point, and all the transformations and actions take place on the Worker nodes.
Here’s a breakdown of the key components:
- Driver Program: This is the gate way of your PySpark application. It’s where you write your pyspark code. The driver program is responsible for:
- Creating the SparkContext.
- Defining the transformations and actions on your data.
- Coordinating with the Cluster Manager to allocate resources.
- Scheduling the tasks to be executed on the worker nodes.
- SparkContext: The SparkContext is the heart of a PySpark application. It represents the connection to the Spark cluster. Any Spark functionality you use needs a SparkContext. It is responsible for:
- Connecting to the Cluster Manager.
- Creating RDDs, DataFrames and Datasets.
- Broadcasting variables and adding files to be used on cluster nodes.
- Cluster Manager: The Cluster Manager is responsible for allocating the cluster’s resources across applications. Spark supports various cluster managers, including:
- Standalone: Spark’s own simple cluster manager.
- Apache Mesos: A general-purpose cluster manager.
- Hadoop YARN: The resource management layer of Hadoop.
- Kubernetes: An open-source container-orchestration system.
- Worker Nodes: These are the machines in the cluster that execute the tasks assigned by the driver program. Each worker node can run one or more executors.
- Executors: Executors are processes that run on worker nodes and are responsible for:
- Executing the tasks assigned by the driver program.
- Storing the data (in memory or on disk) that they process.
- Returning the results of the tasks to the driver program.
How PySpark Works
- The driver program creates a SparkContext, which connects to the Cluster Manager.
- The Cluster Manager allocates resources (worker nodes) to the application.
- The driver program defines the computations (transformations and actions) on the data. These operations are expressed in terms of RDDs, DataFrames, or Datasets.
- The driver program breaks down the computations into tasks and sends them to the executors on the worker nodes.
- The executors process the tasks and store any intermediate results.
- The final results of the computation are sent back to the driver program.
This architecture enables PySpark to distribute data processing across a cluster of machines, allowing it to handle large datasets efficiently.
Hadoop, HDFS & MapReduce (What is PySpark)
What is Hadoop?
Hadoop distributes large files across multiple machines via its Hadoop Distributed File System (HDFS), which handles massive datasets and ensures fault tolerance through data duplication. It employs MapReduce for efficient computations on distributed data, making it essential for big data analytics in Python Spark Tutorial.
- Hadoop is a way to distribute very large files across multiple machines.
- It uses the Hadoop Distributed File System (HDFS)
- HDFS allows a user to work with large data sets
- HDFS also duplicates blocks of data for fault tolerance
- It also then uses MapReduce
- MapReduce allows computations on that data
What is Distributed Storage(HDFS): Python Spark Tutorial
Hadoop Distributed File System (HDFS) is a cornerstone of big data storage, designed to handle immense volumes of data across clusters of computers. In HDFS, data is organized into blocks, typically set at a default size of 128 MB.
These blocks are replicated three times across different nodes in the cluster, ensuring data redundancy and fault tolerance. By distributing blocks across multiple nodes, HDFS minimizes the risk of data loss in the event of a node failure.
Additionally, the distribution of smaller blocks enhances parallel processing capabilities, allowing for efficient computation on distributed data. This architecture not only enables HDFS to manage vast datasets but also facilitates robust data processing and analysis. Overall, HDFS provides a reliable and scalable solution for distributed storage, essential for handling the challenges posed by big data environments of Python Spark Tutorial.
- HDFS will use blocks of data, with a size of 128 MB by default
- Each of these blocks is replicated 3 times
- The blocks are distributed in a way to support fault tolerance
- Smaller blocks provide more parallelization during processing
- Multiple copies of a block prevent loss of data due to a failure of a node
What is MapReduce in Python Spark Tutorial?
MapReduce is a programming model used to process vast amounts of data in parallel across distributed systems, such as Hadoop. It breaks down a computation task into smaller sub-tasks, called maps and reduces, which are distributed across the cluster.
The MapReduce framework comprises two main components: the Job Tracker and multiple Task Trackers. The Job Tracker oversees the execution of the MapReduce job, assigning tasks to available Task Trackers. These Task Trackers, running on worker nodes within the cluster, receive the code from the Job Tracker and allocate CPU and memory resources to execute the tasks.
They also monitor the progress and status of the tasks they manage, ensuring efficient utilization of resources and fault tolerance. By leveraging the distributed computing power of multiple nodes, MapReduce enables parallel processing of data, leading to faster and more scalable data processing tasks. Overall, MapReduce simplifies the development and execution of large-scale data processing applications in distributed environments.
- MapReduce is a way of splitting a computation task to a distributed set of files (such as HDFS)
- It consists of a Job Tracker and multiple Task Trackers
- The Job Tracker sends code to run on the Task Trackers
- The Task trackers allocate CPU and memory for the tasks and monitor the tasks on the worker nodes
Apache Spark vs MapReduce in Python Spark Tutorial
Now let’s understand Apache Spark vs MapReduce in Python Spark Tutorial? MapReduce and Spark are both frameworks for distributed data processing, but they differ in several key aspects:
- Storage Requirement:
- MapReduce mandates that files must be stored in Hadoop Distributed File System (HDFS), while Spark is agnostic to storage systems. Spark can process data from various sources, including HDFS, but it doesn’t require data to be stored specifically in HDFS.
- Performance:
- Spark outperforms MapReduce significantly, often achieving speeds up to 100 times faster. This speed advantage is primarily due to Spark’s ability to keep most of the data in memory after each transformation, whereas MapReduce writes intermediate data to disk after each map and reduce operation.
- Memory Utilization:
- Spark optimizes performance by leveraging in-memory computation. It keeps data in memory between transformations, reducing the need for frequent disk reads and writes, which are common in MapReduce. This approach enhances Spark’s processing speed and efficiency.
- Fallback to Disk:
- While Spark primarily operates in memory, it can spill over to disk if the available memory is insufficient to store all data. This flexibility allows Spark to handle datasets larger than the available memory capacity, mitigating the risk of out-of-memory errors.
Spark’s ability to leverage in-memory computation, coupled with its flexibility in storage, contributes to its remarkable speed advantage over MapReduce. By minimizing disk I/O and maximizing memory utilization, Spark offers a more efficient and agile framework for processing large-scale data analytics tasks.
Highlights of Apache Spark vs MapReduce
- MapReduce requires files to be stored in HDFS, Spark does not!
- Spark also can perform operations up to 100x faster than MapReduce
- So how does it achieve this speed?
- MapReduce writes most data to disk after each map and reduce operation
- Spark keeps most of the data in memory after each transformation
- Spark can spill over to disk if the memory is filled
RDD Spark in Python Spark Tutorial
At the heart of Apache Spark lies the concept of Resilient Distributed Datasets (rdd Spark), which possess four key attributes:
- Distributed Collection of Data: Spark RDDs enable the distribution of data across multiple nodes in a cluster, facilitating parallel processing.
- Fault-tolerant: Spark RDDs automatically recover from failures by recomputing lost partitions based on lineage information, ensuring data resilience.
- Parallel Operation – Partitioned: Spark RDDs are partitioned collections, allowing for parallel processing of data across nodes in the cluster, enhancing computational efficiency.
- Ability to Use Many Data Sources: Spark RDDs can ingest data from various sources, making them versatile for different data processing tasks.
Apache Spark RDDs exhibit immutability, lazy evaluation, and cacheability, enhancing their resilience and efficiency. Spark operations are categorized into two types:
- Transformations: These operations define a sequence of steps to be applied to Spark RDDs, akin to a recipe.
- Actions: Actions execute the defined transformations and return results. This behavior mirrors Spark’s lazy evaluation, where transformations are not immediately computed until an action is invoked.
Creating RDDs
rdd = spark.sparkContext.parallelize([1, 2, 3, 4, 5])RDD Transformations
Transformations create new RDDs from existing ones and are lazy (executed when an action is triggered).
rdd.map(lambda x: x * x).collect()
Output:
[1, 4, 9, 16, 25]PySpark RDD Actions
Actions trigger execution and return results.
rdd.count()
Output:
5Spark DataFrames (Python Spark Tutorial)
Spark DataFrames are a structured collection of data, organized into named columns, similar to a table in a relational database or a data frame in Python. Introduced in Spark 1.3, DataFrames represent a higher-level abstraction built on top of RDDs (Resilient Distributed Datasets) in Apache Spark.
Key features of Spark DataFrames include:
- Structured Data: DataFrames provide a structured representation of data, with named columns and inferred or explicit schema, enabling easy manipulation and analysis of structured data.
- Optimized Processing: DataFrames leverage Spark’s Catalyst optimizer and Tungsten execution engine, which optimize query execution plans and perform efficient in-memory processing, resulting in faster data processing compared to traditional RDDs.
- Ease of Use: DataFrames offer a user-friendly API with a wide range of built-in functions for data manipulation, filtering, aggregation, and analysis. This makes it easier for users familiar with SQL or traditional data manipulation tools to work with large-scale data in Spark.
- Integration: Spark DataFrames seamlessly integrate with various data sources and formats, including JSON, CSV, Parquet, Hive, and relational databases, enabling users to read, write, and process data from diverse sources within the Spark ecosystem.
- Compatibility: DataFrames provide compatibility with other Spark components and libraries, such as Spark SQL, MLlib (Machine Learning Library), and Spark Streaming, allowing for seamless integration of data processing, machine learning, and streaming analytics workflows.
Overall, Spark DataFrames serve as a powerful tool for scalable data processing and analysis in Spark, offering a higher-level abstraction that simplifies complex data tasks while leveraging the distributed computing capabilities of the Spark framework.
data = [("Sachin", 25), ("Rahul", 30), ("Sourav", 28)]
df = spark.createDataFrame(data, ["Name", "Age"])
df.show()Spark SQL
You can use SQL queries with PySpark DataFrames. Firstly you need to transform the dataframe into temp view using createOrReplaceTempView. Finally you can query the temp view using SQL statements.
df.createOrReplaceTempView("persons")
spark.sql("SELECT * FROM persons WHERE Age > 26").show()Data Processing using PySpark
Data processing is a critical step in data analytics. PySpark provides various functions to clean, transform, and analyze data.
Common Data Processing Operations
Handling Missing Data: df.na.drop().show(), df.na.fillna(0).show()
Filtering: df.filter(df.age > 25).show()
Transforming: df.withcolumn(“AgePlusFive”, df.Age + 5).show()
Aggregating: df.groupBy(“City”).agg({“Age”:”avg”}).show()
Joining: df1.join(df2, “ID”, “inner”).show()
Handling Various Data Formats
PySpark supports multiple file formats:
- CSV: df = spark.read.csv(“persons.csv”, header=True, inferSchema = True)
- JSON: df = spark.read.json(“persons.json”)
- Parquet: df = spark.read.parquet(“persons.parquet”)
Advanced Data Operations
Useful for ranking, moving averages:
from pyspark.sql.window import Window
from pyspark.sql.functions import row_number
windowSpec = Window.partitionBy("City").orderBy("Age")
df.withColumn("Rank", row_number().over(windowSpec)).show()Machine Learning with MLlib
Feature Engineering: VectorAssembler, StringIndexer, OneHotEncoder
Classification: LogisticRegression, DecisionTreeClassifier
Regression: LinearRegression, RandomForestRegressor
Clustering: KMeans
Model Evaluation: RegressionEvaluator, BinaryClassificationEvaluator
Spark Streaming
- Structured Streaming: Continuous data processing.
- Reading Streams: spark.readStream.format(“socket”), spark.readStream.format(“kafka”)
- Writing Streams: stream_df.writeStream.format(“console”),
stream_df.writeStream.format(“parquet”)
Performance Optimization
- Caching: df.cache(), df.persist()
- Partitioning: Choosing the right number of partitions.
- Broadcast Variables: broadcast(df)
- Avoiding Shuffles: Optimizing joins and aggregations.
- Tuning Spark Configuration: spark.conf.set()
Conclusion
This guide provides a step-by-step approach to mastering PySpark. Start experimenting with real-world datasets, and soon you’ll be handling big data like a pro!


Pingback: How to Open Parquet File in Python – Enodeas
Pingback: What is Parquet File Format – Enodeas
Pingback: How to Install PySpark on Windows Machine